
Nhiều bạn sinh viên khi thu thập dữ liệu, số liệu báo cáo về dùng để xử lý, phân tích bằng SPSS. Tuy nhiên, bộ số liệu thu thập được lại cho kết quả xấu, không như mong đợi, việc sửa lại bộ số liệu dẫn đến kết quả bị lỗi. Vậy làm cách nào để fake dữ liệu SPSS tốt nhất? Hãy cùng tham khảo ngay 3 cách fake dữ liệu SPSS cho số liệu hoàn chỉnh nhất, đúng chuẩn ở bài viết bên dưới nhé!
1. Tại sao cần Fake dữ liệu SPSS
Dữ liệu khảo sát sau khi đã được thu thập nhưng chưa thể đưa vào xử lý, phân tích ngay bởi vì còn nhiều lỗi cần phải được chỉnh sửa, loại bỏ. Nguyên nhân là do:
- Qua việc khảo sát thu thập thông tin, kết quả cho thấy rằng số liệu thu thập rất xấu, không đáp ứng được yêu cầu, điều kiện để đạt về ý nghĩa thống kê.
- Thường hay gặp phải tình trạng đa cộng tuyến hay không có sự tương quan.
- Các hệ số CR < 0.6, tổng giá trị biến < 0.3. Thêm vào đó là những biến quan sát đột nhiên bị mất..
- Số liệu của EFA không đủ điều kiện để kiểm định, các biến nhân tố bị xáo trộn không theo ý muốn của bạn.
- Nhiều biến cần quan sát bị loại bỏ khá nhiều.
- Biến nhân tố bị loại bỏ không theo ý mình.
- Giá trị R còn quá thấp.
- …..
Các lỗi phát sinh trên có thể vì các lý do chủ quan hoặc khách quan. Nếu như có quá nhiều lỗi trong bộ dữ liệu dẫn đến các kết quả thống kê, phân tích sẽ không chính xác, thậm chí có một số trường hợp lỗi dữ liệu khiến cho toàn bộ dữ liệu khảo sát bị sai hoàn toàn phải thu thập lại.
2. Cách fake dữ liệu SPSS bằng chỉ định Min và Max
Ví dụ ta có bảng số liệu đã thu thập được, ít nhất có một biến để chúng ta tiến hành fake dữ liệu SPSS.
Bên dưới là các bước hướng dẫn các bước fake dữ liệu chi tiết nhất:
Bước 1: Trên thanh công cụ SPSS, ta ấn vào Transform -> Compute Variable. Hộp thoại Compute Variable sẽ hiện ra:
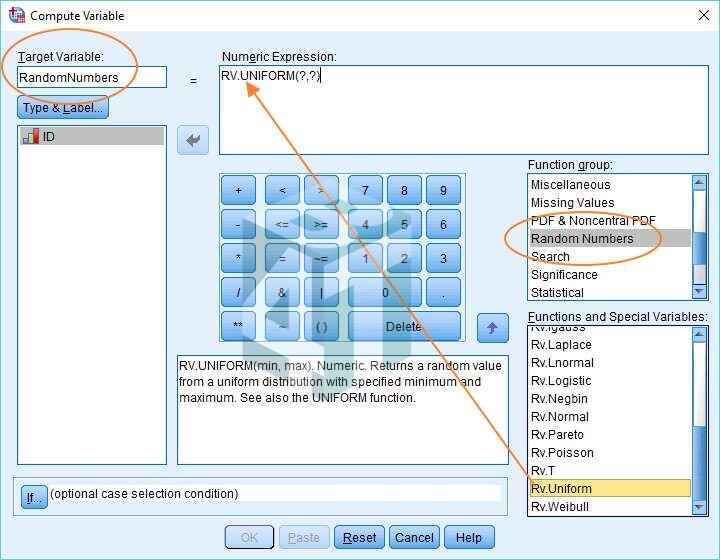
- Đầu tiên các bạn hãy đặt tên cho biến mới của mình. Ở bài viết này chúng tôi sẽ đặt tên là “RandomNumbers”. Đây là biến mà SPSS sẽ tạo ra để giữ tập hợp các số ngẫu nhiên.
- Hàm chúng ta sẽ chọn là hàm Rv.Uniform. Thao tác này trả về một giá trị ngẫu nhiên từ một phân bố đồng nhất với giá trị lớn nhất và giá trị lớn nhất đã xác định. Hoặc, nói một cách khác, nó sẽ tạo ra một số ngẫu nhiên giữa hai giới hạn, trong đó mọi giá trị có thể có giữa các giới hạn đều có khả năng được tạo ra như nhau.
- Cần phải đưa hàm Rv.Uniform vào hộp Biểu thức số ở đầu hộp thoại. Bạn có thể kéo và thả (như trên) hoặc sử dụng mũi tên lên ở giữa hộp thoại.
Bước 2: Sau khi bạn kéo Rv.Uniform. Chức năng thống nhất vào biểu thức số hộp, bạn sẽ nhận thấy nó có hai dấu chấm hỏi sau nó (xem ở trên). Điều này báo hiệu rằng bạn cần chỉ định các giá trị tối thiểu và tối đa cho các số ngẫu nhiên của mình.
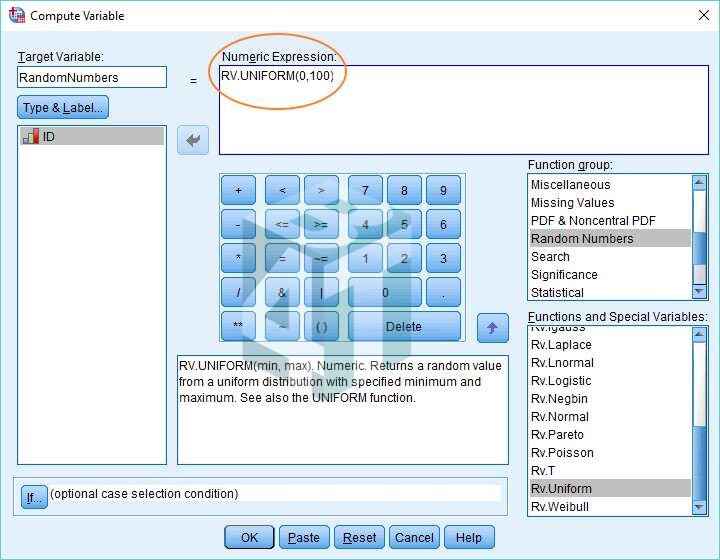
- Điều này rất dễ thực hiện. Chỉ cần thay thế mỗi dấu chấm hỏi bằng một giá trị. Chúng tôi đã chọn 0 làm mức tối thiểu và 100 làm mức tối đa (như trên).
- Điều đó hoàn thành việc thiết lập. Chỉ cần nhấn OK để tạo biến chứa tập hợp các số ngẫu nhiên (trong trường hợp này là từ 0 đến 100).
Bước 3: Bấm vào OK. Kết quả sẽ được hiển thị. Như các bạn có thể thấy bên dưới, SPSS đã tạo ra một biến mới được gọi là “RandomNumbers” và trong đó là các số ngẫu nhiên, mỗi số có giá trị từ 0 đến 100.
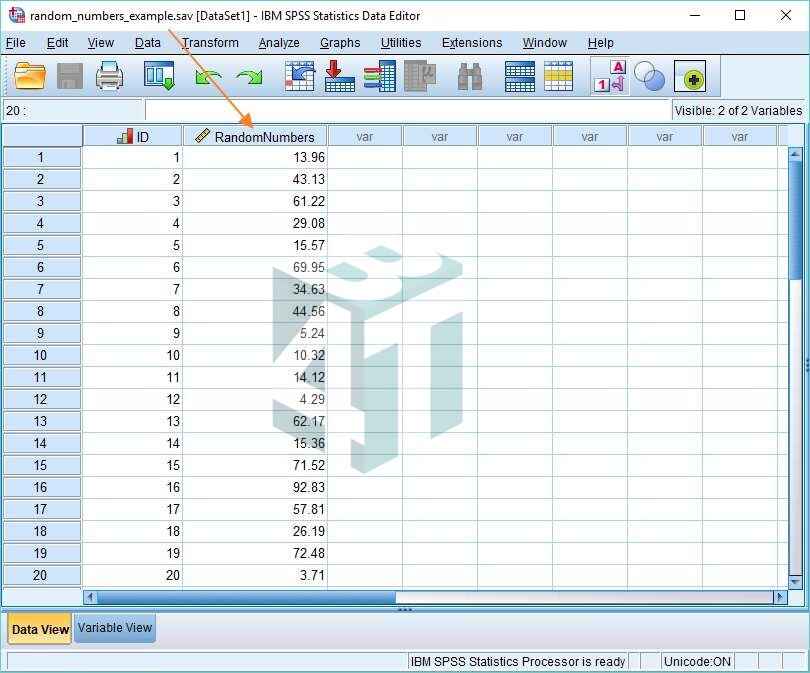
Một điều cần lưu ý ở đây là mặc dù bạn chỉ nhìn thấy 2 chữ số thập phân, SPSS đã thực sự tính toán các số với độ chính xác cao hơn nhiều (bạn sẽ thấy nếu bạn chọn một ô riêng lẻ). Điều này có nghĩa là rất khó có khả năng bạn sẽ nhận được một số trùng lặp.
3. Cách fake dữ liệu SPSS bằng cách sử dụng các số ngẫu nhiên
Xét ví dụ: Bạn đã tuyển dụng ba mươi người cho một nghiên cứu y tế. Bạn muốn phân bổ những người này để điều trị và kiểm soát các điều kiện trên cơ sở ngẫu nhiên. Làm thế nào để các bạn fake dữ liệu bằng cách sử dụng SPSS?
Bên dưới là các bước hướng dẫn để fake dữ liệu:
Bước 1: Trên thanh công cụ của SPSS, ta bấm chọn phần Transform -> Compute Variable. Hộp thoại Compute Variable sẽ hiện ra:
- Đầu tiên các bạn cần làm là đặt tên cho biến mục tiêu của mình. Ở phần này chúng tôi sẽ đặt tên là “TreatmentGroup”.
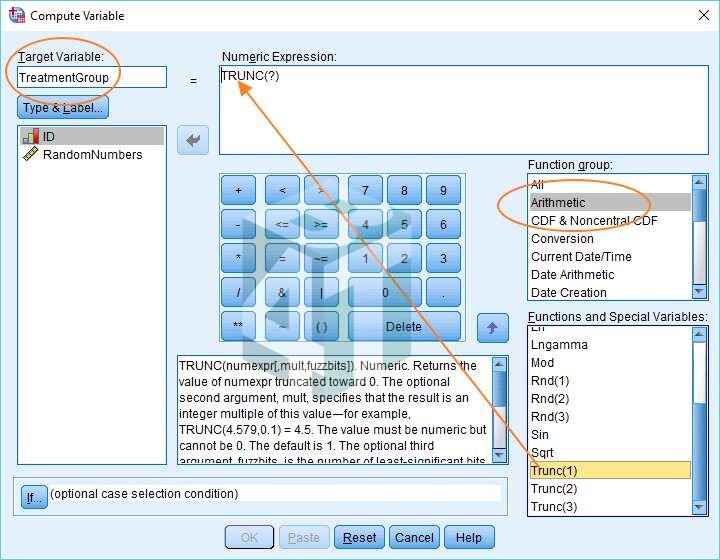
- Sau khi đã đặt tên, các bạn hãy chọn Arithmetic trong Function group ở bên trái, sau đó cuộn xuống chọn hàm Trunc(1).
- Hàm Trunc(1) này có tác dụng làm tròn bất kỳ số thập phân nào xuống thành số không. Hoặc nói cách khác, nó cắt ngắn số thập phân để chỉ còn lại phần nguyên của số. Ví dụ: 2, 91 sẽ trở thành 2 và 3, 33 sẽ trở thành 3.
- Như hình trên, các bạn phải đưa hàm này vào phần Numeric Expression, bạn có thể thực hiện việc này bằng cách kéo và thả.
- Bạn sẽ nhận thấy có một dấu chấm hỏi ngay sau hàm Trunc trong hộp Numeric Expression. Đây là khoảng trống cho giá trị sẽ bị cắt bớt.
Bước 2: Tiếp tục ở phần Numeric Expression, chúng ta sẽ cắt bớt một số ngẫu nhiên nằm trong khoảng từ 0 đến 2. Lý do tại sao sẽ trở nên rõ ràng trong thời gian ngắn.
- Để làm điều này, chúng ta sẽ sử dụng thêm hàm RV. Chức năng thống nhất như chúng ta đã sử dụng trước đây. Lần này chúng ta hãy chỉ cần nhập nó vào, nhưng với 0 và 2 là giá trị Min và Max. Nó sẽ thay thế dấu chấm hỏi xuất hiện giữa các dấu ngoặc ở cuối hàm Trunc trong hộp thoại Numeric Expression.
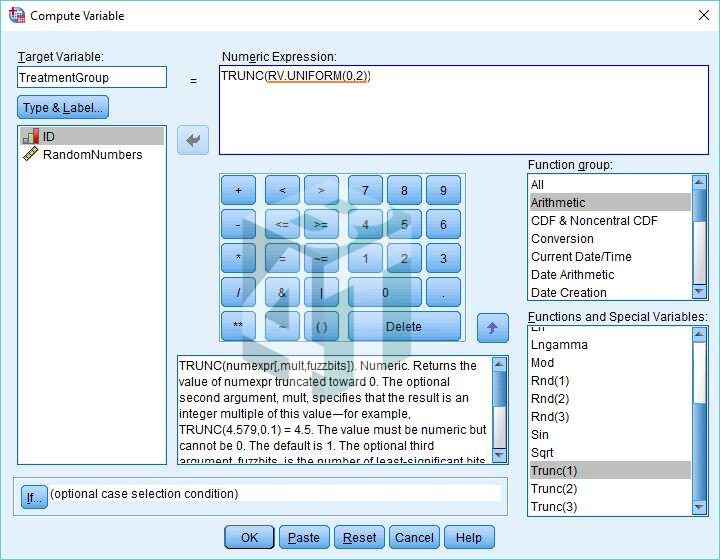
- Tóm lại, RV. Hàm UNIFORM(0,2) sẽ tạo ra một tập hợp các số ngẫu nhiên từ 0 đến 2. Hàm cắt bớt sẽ loại bỏ phần thập phân của mỗi số chỉ để lại phần nguyên.
Bước 3: Bấm vào OK, kết quả sẽ hiển thị như hình bên dưới:
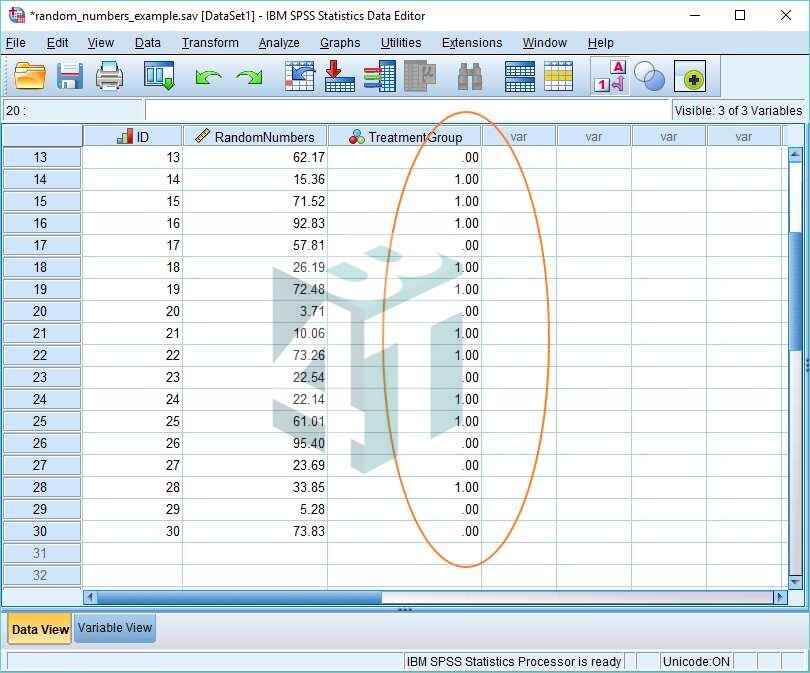
- Như bạn có thể thấy, SPSS đã tạo ra một biến mới được gọi là “TreatmentGroup” và trong mọi trường hợp, giá trị là 0 hoặc 1. (Về mặt lý thuyết có thể nhận được 2, nhưng rất khó xảy ra.) Điều này là do hàm cắt cụt đã làm tròn mọi giá trị được tạo ngẫu nhiên từ 0 đến 1 xuống 0 và mọi giá trị được tạo ngẫu nhiên từ 1 đến 2 xuống 1.
- Trong tình huống này, 1 có nghĩa là điều kiện điều trị và 0 điều kiện kiểm soát, vì vậy chúng tôi đã đạt được mục tiêu phân bổ ngẫu nhiên mọi người vào điều kiện điều trị và kiểm soát. Tuy nhiên, bạn có thể muốn dọn dẹp mọi thứ một chút bằng cách vào Variable View và thiết lập lại giá trị (1 = Điều trị, 0 = Kiểm soát).
4. Cách fake dữ liệu SPSS bằng phân phối trung bình
Xét ví dụ: Hãy tưởng tượng bạn muốn chạy một mô phỏng cấp độ dân số về hiệu quả của các lựa chọn điều trị khác nhau cho một bệnh cụ thể và bạn biết rằng hiệu quả của thuốc bị ảnh hưởng bởi trọng lượng của bệnh nhân. Trong tình huống này, bạn sẽ muốn mô hình dân số của mình phản ánh sự phân bố trọng số của mọi người trong thế giới thực.
- Chúng ta đã biết trọng lượng thường được phân phối, có nghĩa là miễn là chúng ta biết giá trị trung bình và độ lệch chuẩn của phân phối, chúng ta có thể tạo ra một phân phối ngẫu nhiên các trọng số trong SPSS sẽ phù hợp với đặc điểm phân phối trọng số trong thế giới thực.
- Đây là cách chúng tôi sẽ làm điều này đối với người trưởng thành, giả sử rằng trọng lượng trung bình của một người trưởng thành là 195 lbs và độ lệch chuẩn của sự phân bố trọng lượng là 35 lbs.
Bên dưới là các bước hướng dẫn cụ thể cách fake dữ liệu SPSS:
Bước 1: Trên thanh công cụ của SPSS, ta bấm chọn phần Transform -> Compute Variable. Hộp thoại Compute Variable sẽ hiện ra:
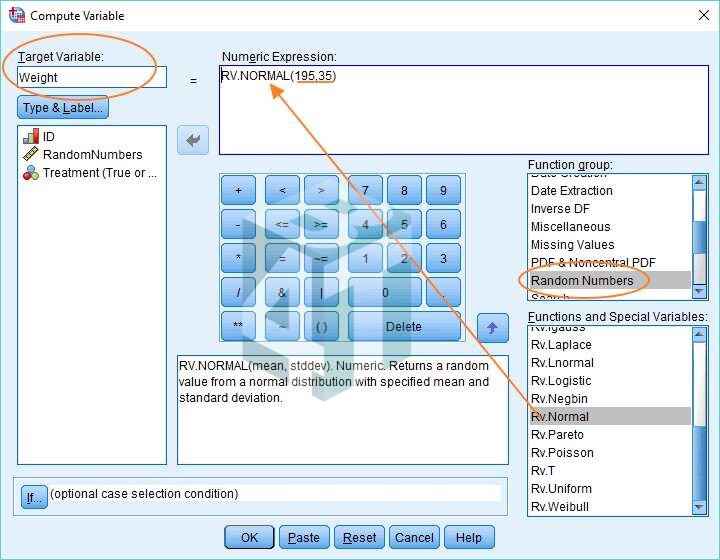
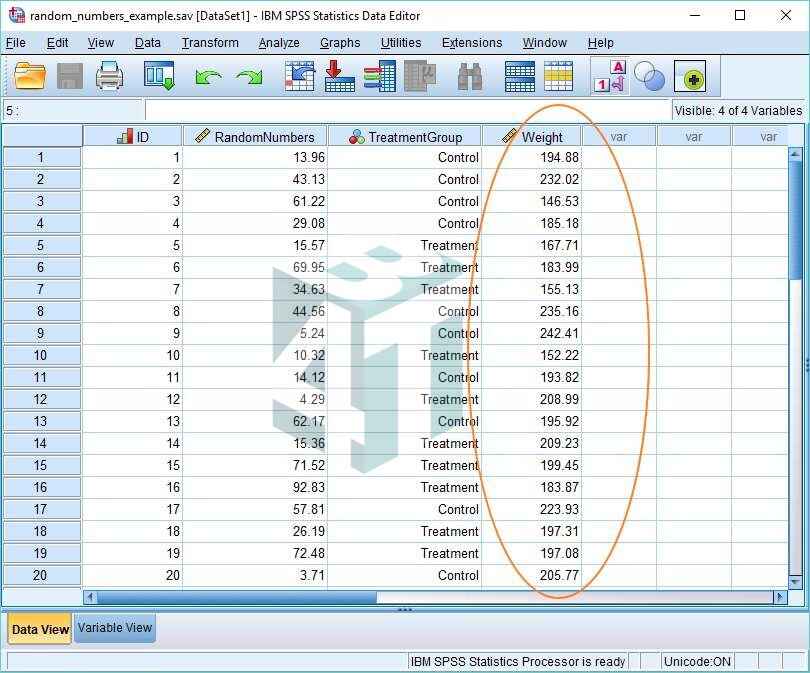
- Đầu tiên, đặt tên cho biến Target Variable của bạn (chúng ta có “Weight” làm tên biến). sau đó, chọn Random Numbers trong the Function group và trong hộp thoại Functions and Special Variables, cuộn xuống kéo hàm RV.Normal lên trên Numeric Expression. Thay thế dấu chấm hỏi đầu tiên bằng 195, là trọng số trung bình và dấu chấm hỏi thứ hai bằng 35, là độ lệch chuẩn.
Bước 2: Nhấn OK và SPSS sẽ tạo ra một biến gọi là “Weight” và điền vào nó là các trọng lượng phân phối bình thường như hình bên dưới:

5. Lưu ý khi Fake dữ liệu SPSS
– Phải đảm bảo dữ liệu bạn thu thập đã nhập đúng, chính xác vào phần mềm SPSS trước khi fake dữ liệu
– Dữ liệu sau khi fake chưa đảm bảo sẽ cho ra số liệu đúng, tuy nhiên các bạn có thể fake lại nhiều lần để cho ra bộ số liệu mà mình ưng ý nhất.
– Bảng câu hỏi của các bạn phải lấy từ nguồn rõ ràng, từ các số liệu của nghiên cứu lớn đã được nhiều nhà nghiên cứu công nhận. Các câu hỏi thu thập thông tin của bạn cũng cần được giảng viên đánh giá và chấp nhận thì lỗi xuất hiện phần lớn là do người được khảo sát. Về phần chi phí khảo sát không hề nhỏ, chính vì vậy ở trường hợp sẽ gây khó khăn cho chúng ta nếu phải đi thể khảo sát lại. Do vậy, các bạn cần nên tập trung loại bỏ những bảng câu hỏi xấu, thu thập thiếu thông tin để cải thiện số liệu của mình hơn.
– Các bạn nên tìm và loại bỏ bớt các biến có yếu tố tương quan mạnh với nhau, vì đây có sự trùng lặp dữ liệu.
– Nếu các câu hỏi bảng khảo sát có vai trò quan trọng và không thể loại bỏ, chỉ còn cách đó là bạn phải chỉnh sửa số liệu, các bạn đừng nên để số liệu biến quan sát trong nhân tố giống hơn 70% so với các số liệu biến quan sát trong nhân tố khác.
Như vậy, bài viết trên đã tổng hợp 3 cách fake dữ liệu SPSS chi tiết nhất cũng như khái niệm và lưu ý khi fake dữ liệu. Hy vọng sẽ giúp ích được cho các bạn. Chúc các bạn đạt kết quả cao!







